Robo-ABC
 :
Affordance Generalization
Beyond
Categories via Semantic
Correspondence for
Robot Manipulation
:
Affordance Generalization
Beyond
Categories via Semantic
Correspondence for
Robot Manipulation
|
|
1Shanghai Qi Zhi Institute 2IIIS, Tsinghua University 3School of Software, Tsinghua University |
4Shanghai Jiao Tong University 5Shanghai AI Lab |
💐 ECCV 2024 🐱 |
*Equal contribution |
|
Abstract
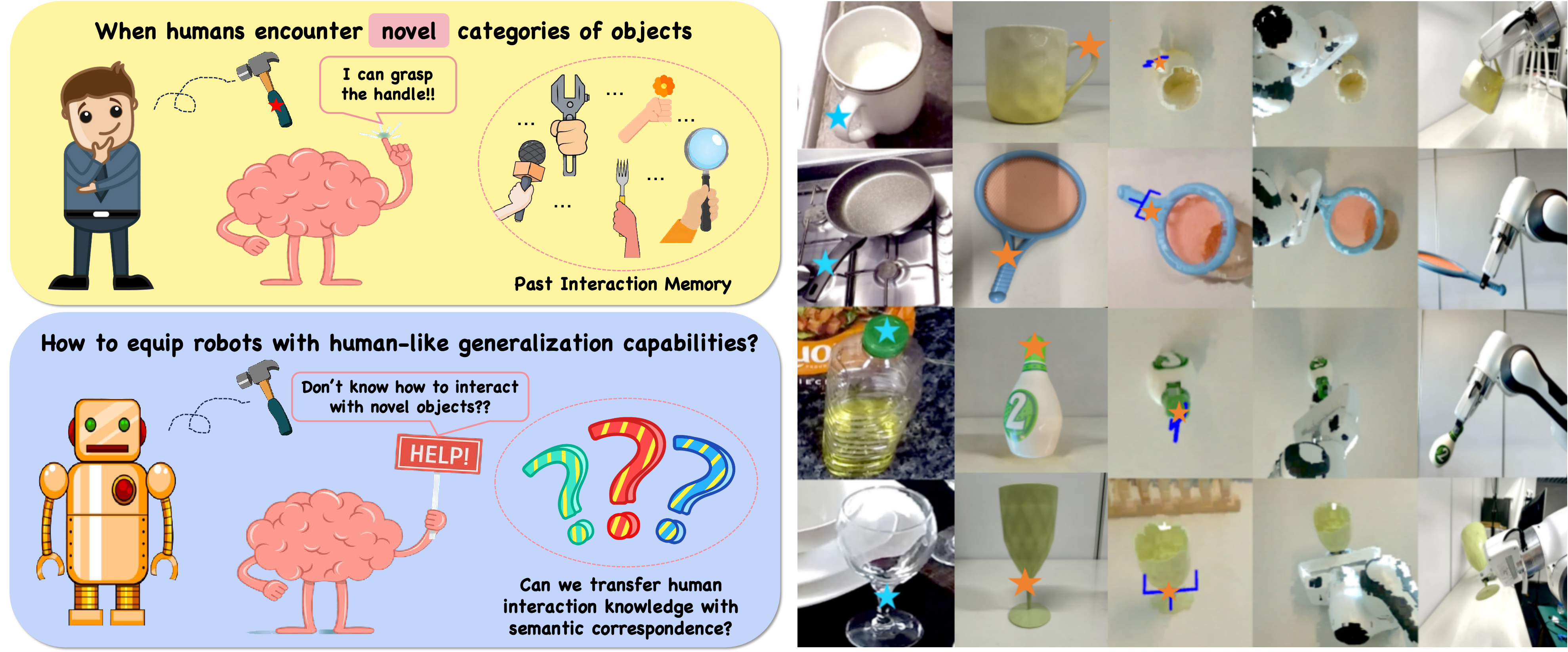
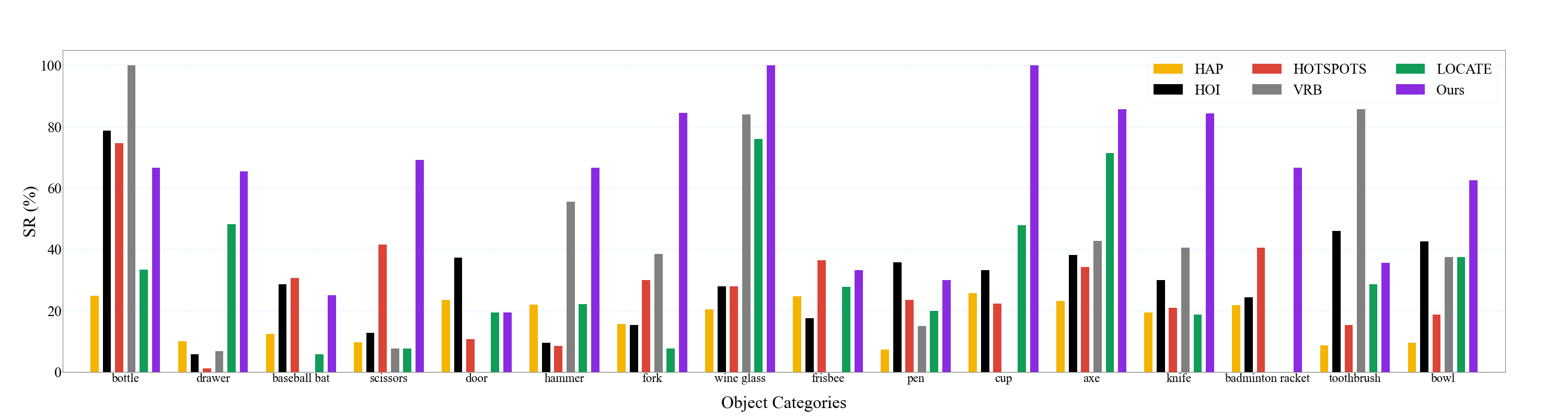
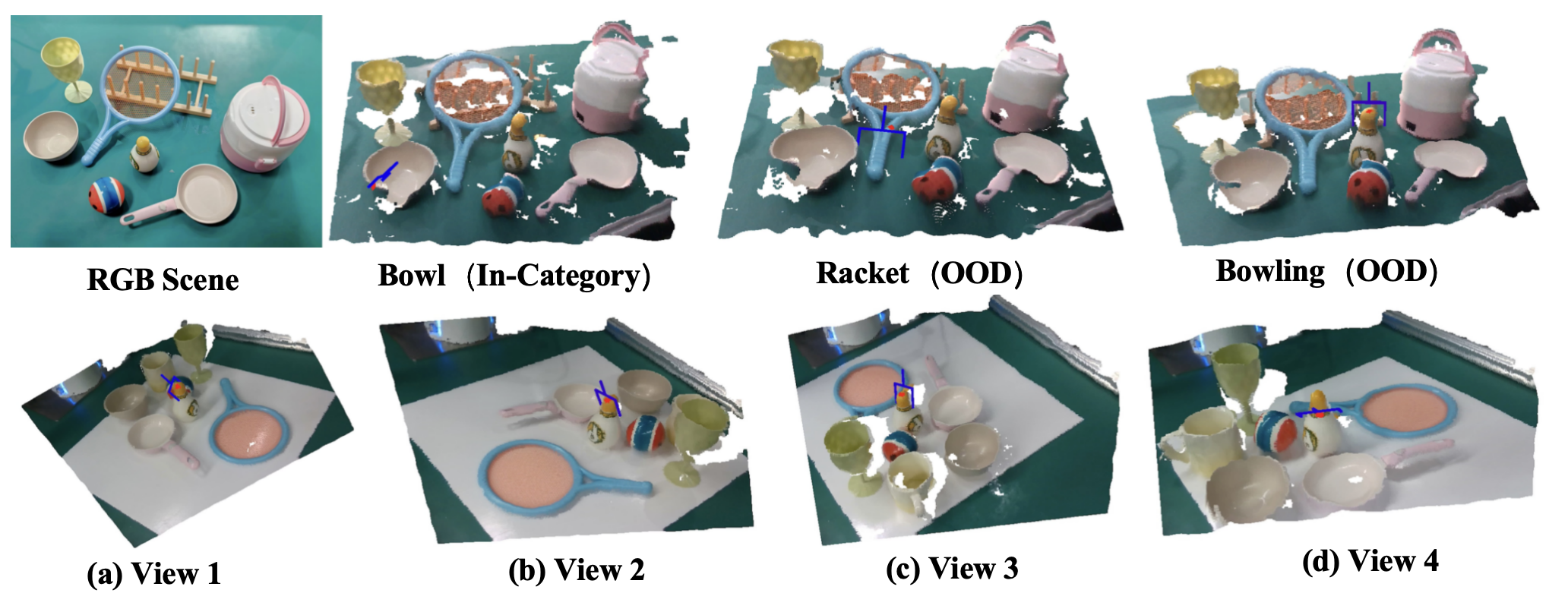
Enabling robotic manipulation that generalizes to out-of-distribution scenes is a crucial step toward open-world embodied intelligence. For human beings, this ability is rooted in the understanding of semantic correspondence among objects, which naturally transfers the interaction experience of familiar objects to novel ones. Although robots lack such a reservoir of interaction experience, the vast availability of human videos on the Internet may serve as a valuable resource, from which we extract an affordance memory including the contact points.